案例篇(50~58篇)
Contents
50.案例篇|动态追踪怎么用?(上)
动态追踪技术,通过探针机制,来采集内核或者应用程序的运行信息,从而可以不用修改内核和应用程序的代码,就获得丰富的信息,帮你分析、定位想要排查的问题。
1. 动态追踪的事件源
动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类
- 硬件事件,通常由性能监控计数器PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如CPU的缓存、指令周期、分支预测等等。
- 静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。
- 动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的kprobes和用于用户态的uprobes。
2. 动态追踪机制
Linux提供了一系列的动态追踪机制,比如 ftrace、perf、eBPF 等。
2.1 ftrace
ftrace 5步骤:
|
|
|
|
trace-cmd
|
|
2.2 perf
perf可以用来分析CPU cache、CPU迁移、分支预测、指令周期等各种硬件事件; perf也可以只对感兴趣的事件进行动态追踪。
|
|
2.3 eBPF 和 BCC
eBPF追踪的工作原理
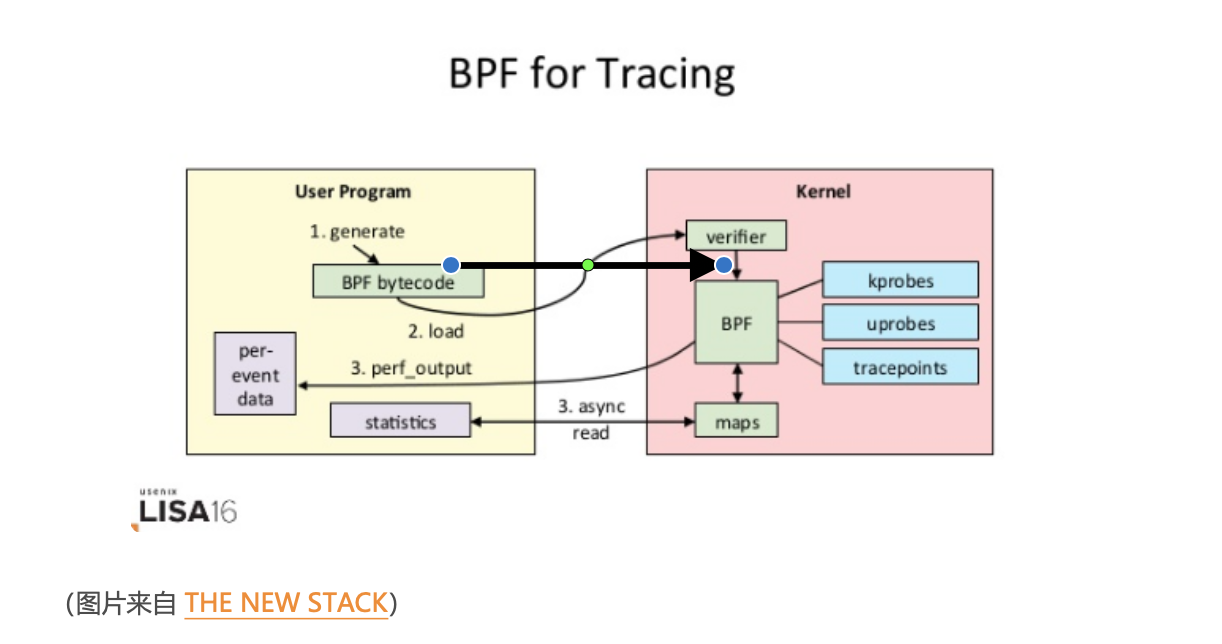 eBPF 的执行需要三步:
eBPF 的执行需要三步:
- 从用户跟踪程序生成 BPF 字节码;
- 加载到内核中运行;
- 向用户空间输出结果。
53.套路篇|系统监控的综合思路
如何对 Linux 系统进行监控
1. USE 法
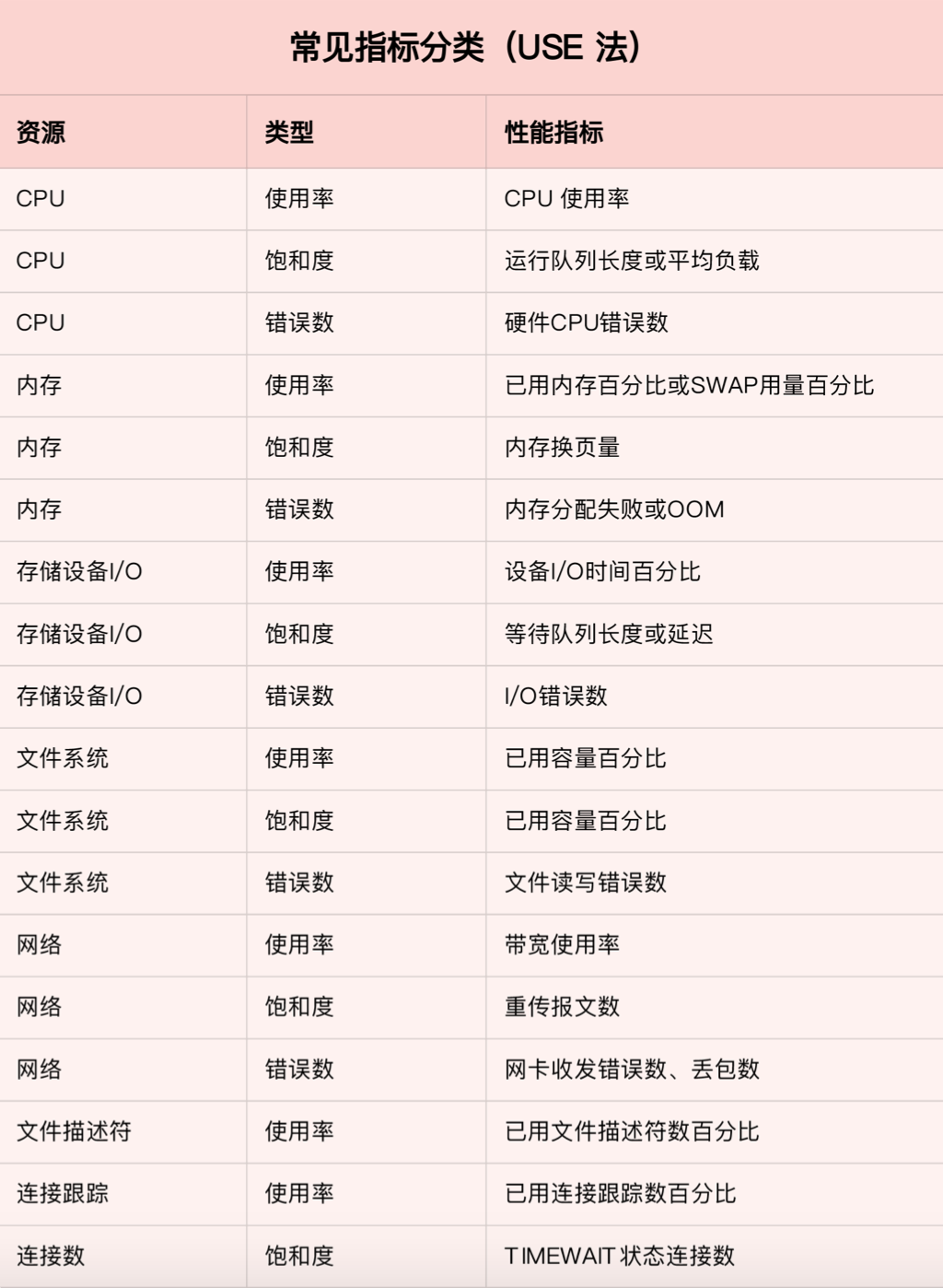
USE(Utilization Saturation and Errors)法把系统资源的性能指标,简化成了三个类别,即使用率、饱和度以及错误数。
- 使用率,表示资源用于服务的时间或者容量百分比
- 饱和度,表示资源的繁忙程度,通常与等待队列的长度相关
- 错误数,表示发生错误事件个数
2. 监控系统
掌握USE方法以及需要监控的性能指标后,需要建立监控系统,然后根据这些监控到的状态,自动分析和定位大致的瓶颈来源;最后,再通过告警系统,把问题及时汇报给相关团队处理。
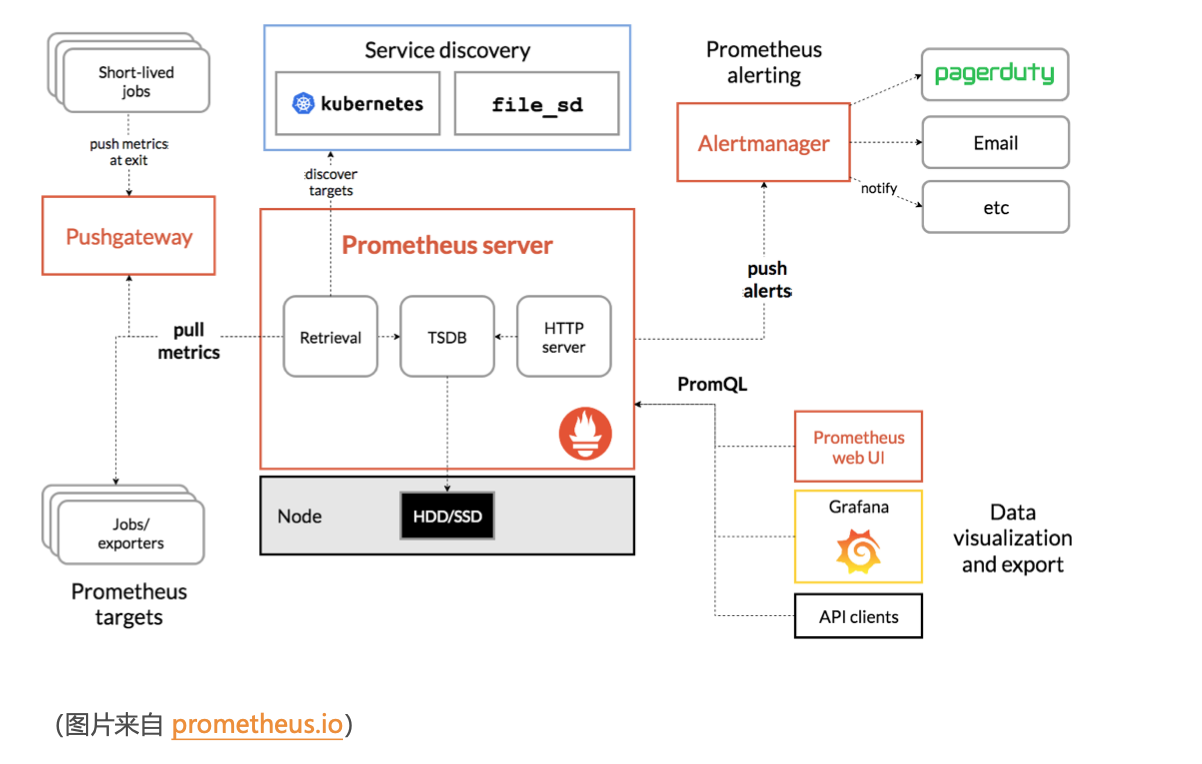
- 先看数据采集模块。最左边的 Prometheus targets 就是数据采集的对象。Prometheus 同时支持 Push 和 Pull 两种数据采集模式。
- Pull 模式,由服务器端的采集模块来触发采集。只要采集目标提供了 HTTP 接口,就可以自由 接入(这也是最常用的采集模式)。
- Push 模式,则是由各个采集目标主动向 Push Gateway(用于防止数据丢失)推送指标,再由服务器端从 Gateway 中拉取过去(这是移动应用中最常用的采集模式)。
- 第二个是数据存储模块。为了保持监控数据的持久化,图中的 TSDB(Time series database) 模块,负责将采集到的数据持久化到 SSD 等磁盘设备中。
- 第三个是数据查询和处理模块。刚才提到的 TSDB,在存储数据的同时,其实还提供了数据查询 和基本的数据处理功能,而这也就是 PromQL 语言。
- 第四个是告警模块。右上角的 AlertManager 提供了告警的功能,包括基于 PromQL 语言的触发条件、告警规则的配置管理以及告警的发送等
- 最后一个是可视化展示模块。Prometheus 的 web UI 提供了简单的可视化界面,用于执行 PromQL 查询语句,但结果的展示比较单调。不过,一旦配合 Grafana,就可以构建非常强大的 图形界面了。
54.套路篇|应用监控的一般思路
1. 指标监控
- 第一个,是应用进程的资源使用情况,比如进程占用的 CPU、内存、磁盘 I/O、网络等。
- 第二个,是应用程序之间调用情况,比如调用频率、错误数、延时等。由于应用程序并不是孤立 的,如果其依赖的其他应用出现了性能问题,应用自身性能也会受到影响。
- 第三个,是应用程序内部核心逻辑的运行情况,比如关键环节的耗时以及执行过程中的错误等。
55.套路篇|分析性能问题的一般步骤
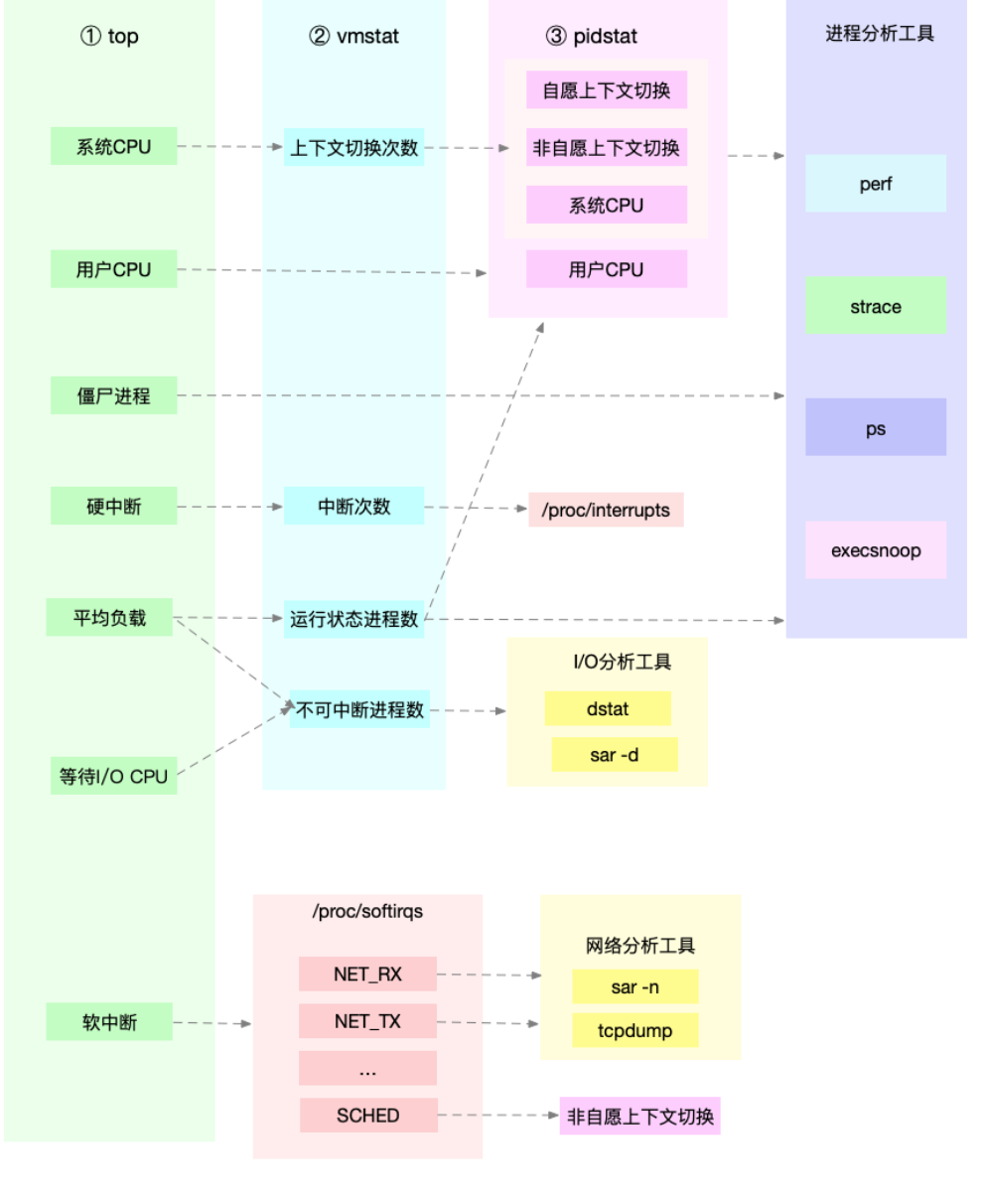
CPU性能分析
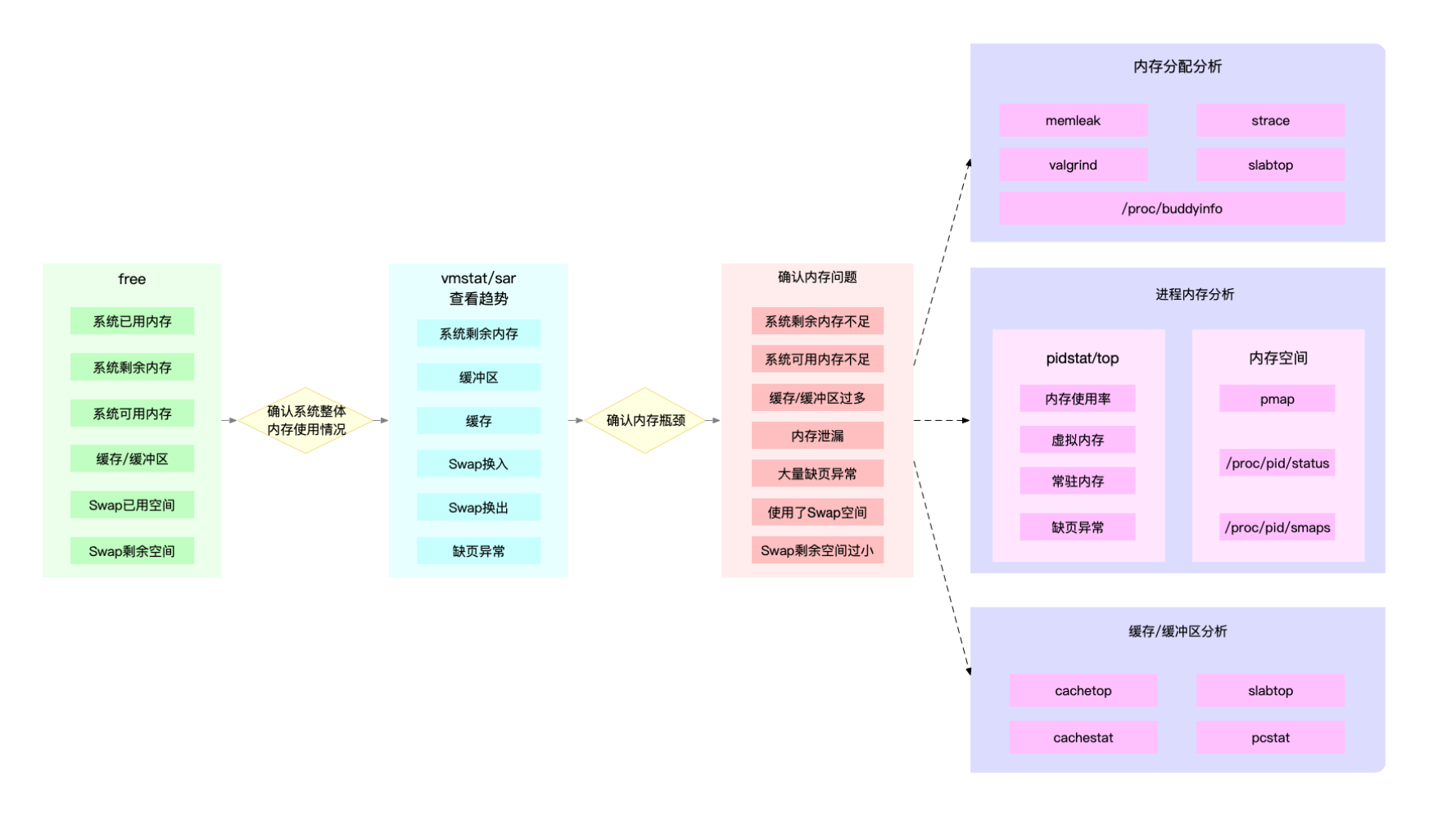
内存性能分析
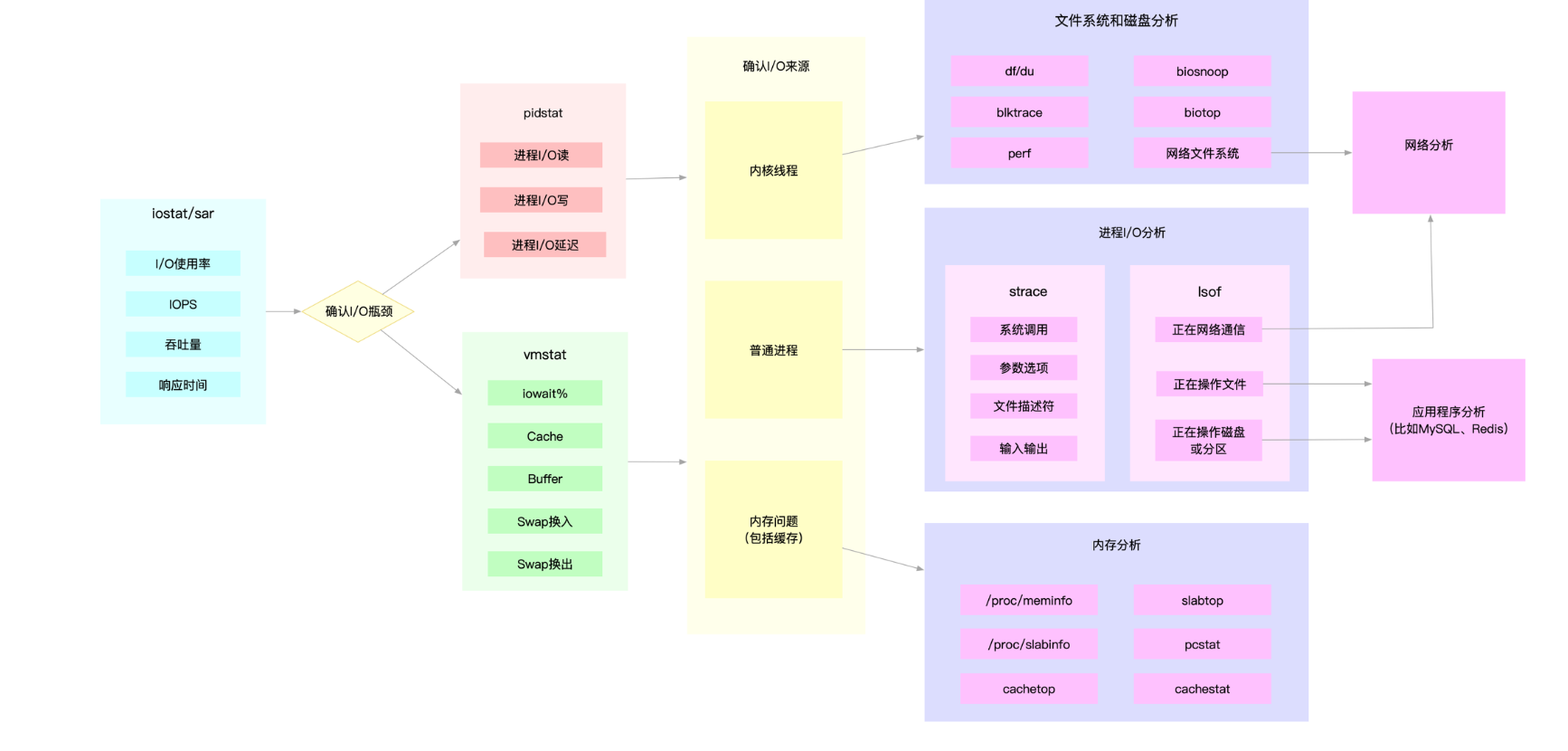
磁盘和文件系统 I/O 性能分析
网络性能分析
- 在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析; 在网络层,可以从路由、分片、叠加网络等角度进行分析;
- 在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行 分析;
- 在应用层,可以从应用层协议(如 HTTP 和 DNS)、请求数(QPS)、套接字缓存等角度进 行分析。
应用程序瓶颈
应用程序瓶颈的本质:资源瓶颈、依赖服务瓶颈以及应用自身的瓶颈。
56.套路篇|优化性能问题的一般方法
Author zhuyhan
LastMod 2020-07-17